
How does the internet work?
In this post, I'm going to give you a simple explanation of how the internet works. This is the first in a series of posts that introduce readers to modern web programming.
TLDR: It's just computers talking to each other
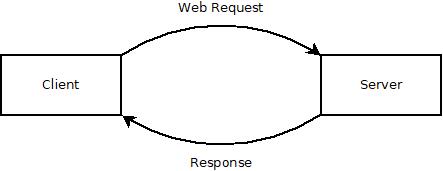
When using the internet, one device requests a piece of information that is stored on a computer connected to the internet, and that computer returns it to the requesting device. The modern web is much more complex than that, but at it's simplest level it's just computer A requesting information from computer B.
The requesting device is usually called the client. The computer that serves the request is usually called a server. So if you have to remember one thing about how the web works, just remember this:
Clients request information that is stored on servers. Servers return that information to the clients.
What is a client?
The "client" we're actually talking about is a web browser. The web browser knows how to do several things. Here's some of the things that a web browser can do.
- Build a request for information using a language, or protocol, called HTTP.
- Send that request to servers on the internet by using the operating system to access network resources.
- Parse a response to an HTTP request that sometimes includes a web page.
- Display a web page made of html, css, and javascript.
- Interpret events fired by the operating system that come from devices such as keyboards, touchscreens, and mice.
That's just a bare fraction of what the client does, but it shows that modern web browsers are technical marvels.
What is a server?
The job of the server is slightly different. The server runs a piece of software that listens snd responds to incoming web requests. Such software is called a web server and it includes Apache, Node, and nginx. When it receives a web request, it seeks the resource that corresponds to the requested information to try to fulfill the request.
In the very early days of the web, the resources were just files. So a client might make a request for "/schedule.txt" and the server would see if it had such a file, and return it if it did.
How does the client know where to find the server?
Before the client can make a request to a server, it has to know which server has the information that it is seeking. It does this by using a service called Domain Name System, or just DNS for short.
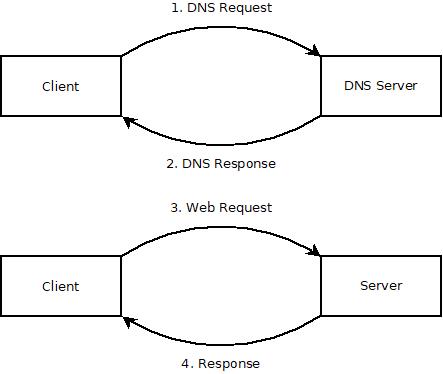
Before the web browser makes the main web request, it makes an initial request to your internet service provider, or ISP, to ask where to find that information. So let's look at how this might work when you request "google.com".
- The web browser transforms "google.com" into "http://www.google.com". The "http" stands for Hyper Text Transfer Protocol, and that's the format of the request. The "www" is just an old fashioned naming system that stands for "World Wide Web". When someone sets up a "www" subdomain, they're essentially saying that that address should be publicly available on the internet.
- The web browser then sends a request to your DNS to learn the address for "http://www.google.com". That request goes to a DNS server, which responds with an IP address, which is essentially like a telephone number for a computer. So the request for the address for "http://www.google.com" might return something like "123.456.78.910".
- The web browser then sends a request to the indicated IP address, "123.456.78.910". Then the server does whatever it needs to do to fulfill the request, more on this later, and returns the requested information to the client.
- The client renders the page returned from the server.
Okay, so this is getting a little bit more complex, but it still follows the same model. The web browser first sends a web request to the DNS, then it sends the web request for the specific piece of information.
What does the server actually do?
There is a lot that I am glossing over in this explanation, because I'm trying to keep it simple. I will write future posts that go into a little more detail about how the client and server work, and show how code comes into play in those processes.
But we can break the action of the web server into several steps.
- It validates the request to ensure that it's a request that it can fulfill.
- It locates the requested resource. If no resource is requested, then it seeks a default, which is usually "index.html".
- It reads the requested resource, checking to see if it needs any additional information.
- It uses attached data sources such as databases or caches to request information needed to render the resource.
- It builds the final response incorporating the requested resource as well as any data requested from data sources.
But how does it actually put all of this together? It's the job of a web programmer to tell the server how to assemble a web page that fulfills the user's request.
I want to restate that because that's why we study the web. We care about how the web works so that we can contribute to making it more useful.
It's the job of web programmers to write instructions for web servers to fulfill web requests.
Summary
In this post, I gave a concise overview of how the internet works. Here are the main takeaways.
- When using the internet, a client makes a request for a resource that is stored on a server.
- The client knows how to make web requests and render the response using html, css, and javascript.
- The server uses web software to build web pages using by filling in information from connected data sources.
- DNS servers tell web browsers where to find the web address they are seeking.