
Introduction to HTML
In this post, I'm going to introduce HTML, and demonstrate how it acts as the skeleton for all pages on the internet.
TLDR: HTML defines the structure of the page
HTML is used to define the structure of a web page. It's the structure that your styles (css), and code (JavaScript) sits on top of. The CSS styles the html elements. The code allows interaction with html elements.
What is HTML?
HTML stands for Hyper Text Markup Language. The unusual phrase "hyper text" means "more than text". Hyper text can be contrasted to plain text. You read plain text in a printed book. The words string together to form a story. But what if you want to know more about a topic? What if you want a definition for a term? What if you want to email the author? HTML gives web programmers the ability to "mark up" the text in a way that allows web browsers to add additional functionality to a text document.
HTML is one of the key inventions that enabled the web to become so popular. The ability to add cross-references directly in a document enables all sorts of connections and interactions that were formerly impossible. Nearly every page on the internet is made using HTML.
What are HTML elements?
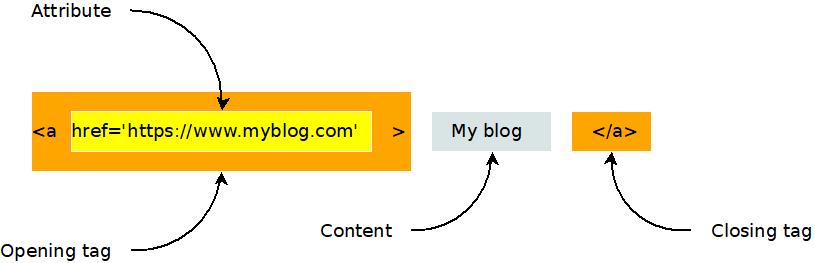
The classic example of a hyper text element is a link. When links were invented, they were called "anchors", as if the author is anchoring a bit of text to another document. When you want to add a link to an html document you use the anchor or "a" element. Here's an example.
<a href='https://www.myblog.com'>My blog</a>
Wow, that's pretty confusing, isn't it? But take a moment to look more closely. What parts of it do you see?
An html element can have an opening tag, any number of attributes, content, and a closing tag, as shown in this diagram.
Here's another example of an html element. It's the image, or "i" element.
<img src="https://www.evanxmerz.com/images/AnchorTag_01.jpg" alt="Anchor tag diagram"/>
Notice that the image element shown here doesn't have a closing tag. This is the shortened form of an html element that doesn't need any content. It ends with "/>" and omits the content and closing tag.
The structure of an html document
HTML documents are composed of numerous html elements in a text file. The HTML elements are used to lay out the page in a way that the web browser can understand.
<!DOCTYPE html>
This must be the first line in every modern html document. It tells web browsers that the document is an html document.
<HTML>
The html element tells the browser where the HTML begins and ends.
<HEAD>
The head element tells the browser about what other resources are needed by this document. This includes styles, javascript files, fonts, and more.
<BODY>
The body element contains the content that will actually be shown to a user. This is where you put the stuff that you want to show to the user.
An example html document
Here's an example html document that contains all of the basic elements that are required to lay out a simple HTML document.
I want you to do something strange with this example. I want you to duplicate it by creating an html document on your computer and typing in the text in this example. Don't copy-paste it. When you copy-paste text, you are only learning how to copy-paste. That won't help you learn to be a programmer. Type this example into a new file. This helps you remember the code and gets you accustomed to actually being a programmer.
What about typos though? Wouldn't it be easier and faster to copy-paste? Yes, it would be easier and faster to copy-paste, however, typos are a natural part of the programming experience. Learning the patience required to hunt down typos is part of the journey.
Here are step-by-step instructions for how to do this exercise on a Windows computer.
- Open Windows Explorer
- Navigate to a folder for your html exercises
- Right click within the folder.
- Hover on "New"
- Click "Text Document"
- Rename the file to "hello_world.html"
- Right click on the new file.
- Hover over "Open With"
- Click Visual Studio Code. You must have installed Visual Studio Code to do this.
Now type the following text into the document.
<!DOCTYPE html>
<html>
<head>
<title>Hello, World in HTML</title>
</head>
<body>
Hello, World!
</body>
</html>
Congratulations, you just wrote your first web page!
Save it and double click it in Windows Explorer. It should open in Google Chrome, and look something like this.
There are many HTML elements
There are all sorts of different html elements. There's the "p" element for holding a paragraph of text, the "br" element for making line breaks, and the "style" element for incorporating inline css styles. Later in this text we will study some additional elements. For making basic web pages, we're going to focus on two elements: "div" and "span".
If you want to dig deeper into some other useful HTML elements, see my post on other useful html elements.
What is a div? What is a span?
That first example is pretty artificial. The body of the page only contains the text "Hello, World!". In a typical web page, there would be additional html elements in the body that structure the content of the page. This is where the div and span elements come in handy!
In the "div" element, the "div" stands for Content Division. Each div element should contain something on the page that should be separated from other things on the page. So if you had a menu on the page, you might put that in a div, then you might put the blog post content into a separate div.
The key thing to remember about the "div" element is that it is displayed in block style by default. This means that each div element creates a separate block of content from the others, typically by using a line break.
<div>This is some page content.</div>
<div>This is a menu or something.</div>
The "span" element differs from the div element in that it doesn't create a new section. The span element can be used to wrap elements that should be next to each other.
<span>This element</span> should be on the same line as <span>this element</span>.
An example will make this more clear.
Another example html document
Again, I want you to type this into a new html file on your computer. Call the file "divs_and_spans.html". Copy-pasting it won't help you learn.
<!DOCTYPE html>
<html>
<head>
<title>Divs and spans</title>
</head>
<body>
<div>
This is a div and <span>this is a span</span>.
</div>
<div>
This is another div and <span>this is another span</span>.
</div>
</body>
</html>
Here's what your page should look like.

It's not very exciting, is it? But most modern webpages are built using primarily the elements I've introduced to you on this page. The power of html isn't so much in the expressivity of the elements, but in how they can be combined in unique, interesting, and hierarchical ways to create new structures.
Summary
In this section I introduced Hyper Text Markup Language, aka HTML. Here are the key points to remember.
- HTML is the skeleton of a web page.
- HTML elements usually have opening and closing tags, as well as attributes.
- HTML documents use the head and body elements to structure the page.
- Div and span elements can be used to structure the body of your webpage.
More
How to set up a computer for web development
In this post, I'm going to suggest a basic set of tools required for web development. These instructions are aimed at people who are using a desktop computer for web development.
TLDR: Install Google Chrome, Visual Studio Code, and npm
Here are links to the three tools that I think are vital to web development.
What tools are needed for web development?
A programmer of any sort needs two basic tools:
- A tool to write code.
- A to to run the code they have written.
Code is usually represented as text, so to write code you will need a text editor. Today most programmers use a text editor that has been adapted for the task of writing code called an Integrated Development Environment, or IDE. The IDE that most programmers prefer in 2023 is Visual Studio Code. It's developed by Microsoft, who has a long history of creating high quality products for developers.
Traditionally, code is compiled and run by a computer's operating system, however, many modern systems take code written by a developer, then run it live using a tool called an interpreter. In this series, we're going to be writing JavaScript code, then running it in the interpreter in Google Chrome or in Node.
So those are the three tools we need to install to setup a basic environment for writing code for the web:
Node also includes a tool that is fundamental to web development called Node Package Manager, or NPM for short. NPM is a tool for downloading chunks of code written by other programmers, or packages, and using them in your own app.
More
Here are some other resources and perspectives on setting up your computer for web programming.
How does the internet work?
In this post, I'm going to give you a simple explanation of how the internet works. This is the first in a series of posts that introduce readers to modern web programming.
TLDR: It's just computers talking to each other
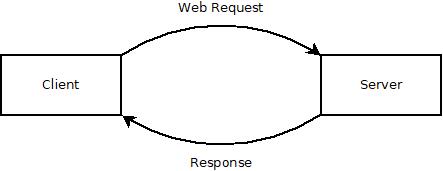
When using the internet, one device requests a piece of information that is stored on a computer connected to the internet, and that computer returns it to the requesting device. The modern web is much more complex than that, but at it's simplest level it's just computer A requesting information from computer B.
The requesting device is usually called the client. The computer that serves the request is usually called a server. So if you have to remember one thing about how the web works, just remember this:
Clients request information that is stored on servers. Servers return that information to the clients.
What is a client?
The "client" we're actually talking about is a web browser. The web browser knows how to do several things. Here's some of the things that a web browser can do.
- Build a request for information using a language, or protocol, called HTTP.
- Send that request to servers on the internet by using the operating system to access network resources.
- Parse a response to an HTTP request that sometimes includes a web page.
- Display a web page made of html, css, and javascript.
- Interpret events fired by the operating system that come from devices such as keyboards, touchscreens, and mice.
That's just a bare fraction of what the client does, but it shows that modern web browsers are technical marvels.
What is a server?
The job of the server is slightly different. The server runs a piece of software that listens snd responds to incoming web requests. Such software is called a web server and it includes Apache, Node, and nginx. When it receives a web request, it seeks the resource that corresponds to the requested information to try to fulfill the request.
In the very early days of the web, the resources were just files. So a client might make a request for "/schedule.txt" and the server would see if it had such a file, and return it if it did.
How does the client know where to find the server?
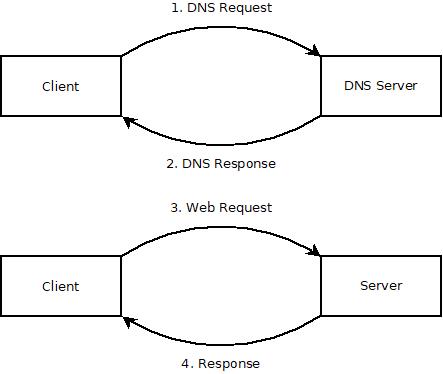
Before the client can make a request to a server, it has to know which server has the information that it is seeking. It does this by using a service called Domain Name System, or just DNS for short.
Before the web browser makes the main web request, it makes an initial request to your internet service provider, or ISP, to ask where to find that information. So let's look at how this might work when you request "google.com".
- The web browser transforms "google.com" into "http://www.google.com". The "http" stands for Hyper Text Transfer Protocol, and that's the format of the request. The "www" is just an old fashioned naming system that stands for "World Wide Web". When someone sets up a "www" subdomain, they're essentially saying that that address should be publicly available on the internet.
- The web browser then sends a request to your DNS to learn the address for "http://www.google.com". That request goes to a DNS server, which responds with an IP address, which is essentially like a telephone number for a computer. So the request for the address for "http://www.google.com" might return something like "123.456.78.910".
- The web browser then sends a request to the indicated IP address, "123.456.78.910". Then the server does whatever it needs to do to fulfill the request, more on this later, and returns the requested information to the client.
- The client renders the page returned from the server.
Okay, so this is getting a little bit more complex, but it still follows the same model. The web browser first sends a web request to the DNS, then it sends the web request for the specific piece of information.
What does the server actually do?
There is a lot that I am glossing over in this explanation, because I'm trying to keep it simple. I will write future posts that go into a little more detail about how the client and server work, and show how code comes into play in those processes.
But we can break the action of the web server into several steps.
- It validates the request to ensure that it's a request that it can fulfill.
- It locates the requested resource. If no resource is requested, then it seeks a default, which is usually "index.html".
- It reads the requested resource, checking to see if it needs any additional information.
- It uses attached data sources such as databases or caches to request information needed to render the resource.
- It builds the final response incorporating the requested resource as well as any data requested from data sources.
But how does it actually put all of this together? It's the job of a web programmer to tell the server how to assemble a web page that fulfills the user's request.
I want to restate that because that's why we study the web. We care about how the web works so that we can contribute to making it more useful.
It's the job of web programmers to write instructions for web servers to fulfill web requests.
Summary
In this post, I gave a concise overview of how the internet works. Here are the main takeaways.
- When using the internet, a client makes a request for a resource that is stored on a server.
- The client knows how to make web requests and render the response using html, css, and javascript.
- The server uses web software to build web pages using by filling in information from connected data sources.
- DNS servers tell web browsers where to find the web address they are seeking.
More
When I'm feeling down...
Sometimes when I'm feeling bad about myself I remember that someone spent the time to rip and upload the music I wrote for a flash game nearly two decades ago. It was for a game called Arrow of Time. And it kicked ass.
How to convert San Jose Sharks or Barracuda vouchers to tickets on Ticketmaster
I prefer to write about art, programming, and artificial intelligence on my blog, but Ticketmaster is so awful that I felt compelled to write this.
The problem is that Ticketmaster makes it nearly impossible to convert ticket vouchers into actual tickets. You might expect this to be a button on the vouchers in your inventory, but it's not there. So then you might look for some utility in your account, or settings, but there's nothing there either. So you might Google how to do it, but you'd find there's no results there either.
The fact is, Ticketmaster encourages people to buy the vouchers then makes it nearly impossible to redeem them. So I'm trying to clarify that for people. Just to set expectations properly, you should expect this to be very difficult, and it only makes sense if you realize that they don't want you to redeem your vouchers.
Steps to turn Ticketmaster vouchers into actual tickets
- Visit https://am.ticketmaster.com/sharks/ or if you are trying to convert tickets for some other team, then put them at the end of the URL. In this case, the Sharks url works for both the San Jose Sharks and the San Jose Barracuda. You might expect the "/barracuda" url to work, but you would be wrong, because Ticketmaster wants to take your money without delivering any actual service.
- Log in by clicking "Sign In" in the upper right.
- Click "Manage Your Tickets" at the bottom of the page.
- Scroll all the way down your list, then click "Select Event" next to "Barracuda Ticket Vouchers". Again, you have to imagine that they're making this as hard as possible to convert, and then it kind of makes sense. The vouchers aren't tickets, you can't use them to get in, yet they are listed with your tickets.
- Click the "Exchange" button at the top of the list.
- Select the vouchers you want to redeem then click "Continue" at the bottom.
- Click "Select Event" next to the game you want to attend.
- Select the section and seats that you want, then hover over your cart and click "Continue". This part can be extremely tricky because Ticketmaster doesn't want you to redeem your vouchers. So you have to choose seats that EXACTLY match the value of your vouchers. You can't choose cheaper or more expensive seats. Also, you can't leave one empty seat in a row (if I were a lawyer I would question this policy in particular).
- Click "Submit"
Summary
For my own sanity, I just want to summarize how stupidly difficult this is.
- You must go to a custom URL that can't be found via link or search. As far as I know, you have to be told this link by a human.
- You must find the vouchers listed with your tickets, by clicking buttons that are at many different positions on the page, appear in multiple different styles, and have wildly varying text.
- You must pick seats that exactly match the very narrow criteria under which Ticketmaster will allow you to exchange them.
It takes a minimum of 11 clicks through a very unintuitive process to convert the vouchers. In my experience, it takes closer to 20 clicks, and around 15 minutes, because finding seats that Ticketmaster will allow you to purchase is quite difficult.
If I can leave you with one piece of advice, it's this: buy tickets at the gate, or from a salesperson for season tickets, and avoid Ticketmaster altogether.